
SQL (Structured Query Language) es un lenguaje de programación que ha sido ampliamente adoptado como el lenguaje estándar para la gestión de bases de datos y MySQL es el sistema derivado más relevante.
Por ello, realizar consultas en MySQL es una de las funciones básicas que debes aprender si recién comienzas a utilizarlo y aquí te mostraremos el proceso.
Prerrequisitos para hacer consultas en MySQL
Es necesario que tengas instalado MySQL o algún gestor de bases de datos similar que maneje SQL.
Además, debes contar con una base de datos y crear las tablas con datos de acuerdo con el diagrama entidad-relación, que se muestra a continuación.
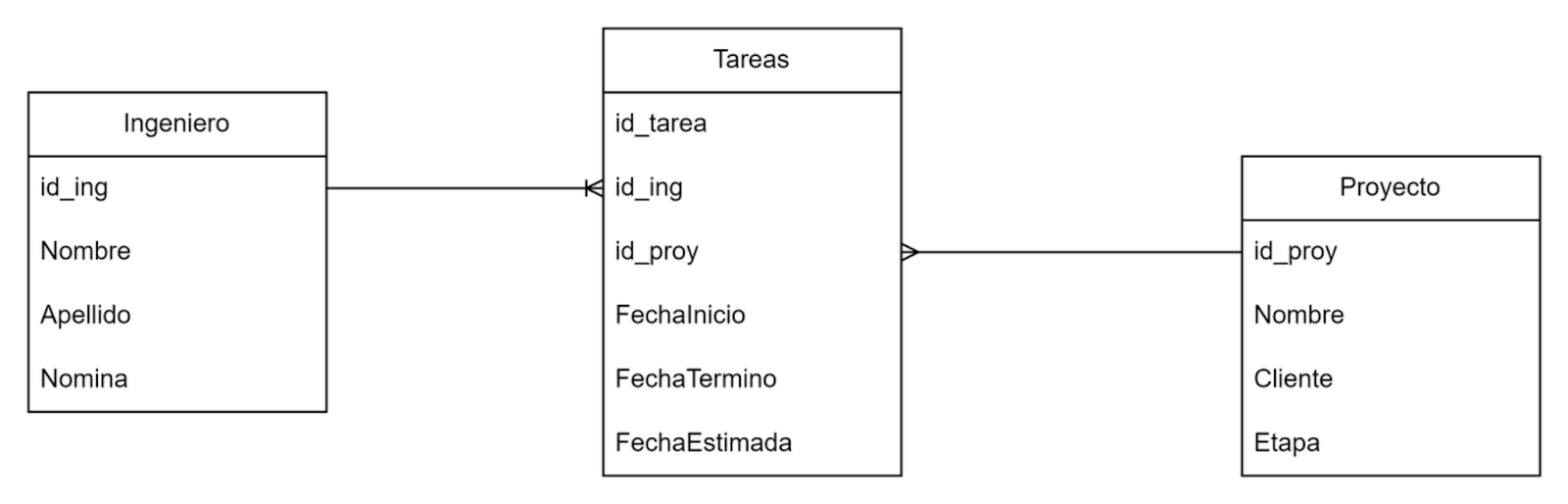
Para crear la base de datos utilizaremos el siguiente comando:
|
CREATE DATABASE proyectosIngenieria; |
Para generar cada una de las tablas de la base de datos, utilizaremos el código que sigue:
|
USE proyectosIngenieria; CREATE TABLE ingeniero ( id INT NOT NULL AUTO_INCREMENT, nombre VARCHAR(50), apellido VARCHAR(50), nomina VARCHAR(10), PRIMARY KEY (id) ); CREATE TABLE proyecto ( id INT NOT NULL AUTO_INCREMENT, nombre_proyecto VARCHAR(50), cliente VARCHAR(50), descripcion TEXT, PRIMARY KEY (id) ); CREATE TABLE tarea ( id INT NOT NULL AUTO_INCREMENT, id_ingeniero INT, id_proyecto INT, fecha_inicio DATE, fecha_termino DATE, fecha_estimada DATE, PRIMARY KEY (id), FOREIGN KEY (id_ingeniero) REFERENCES ingeniero(id), FOREIGN KEY (id_proyecto) REFERENCES proyecto(id) ); |
El comando USE se utiliza para seleccionar la base de datos que estaremos trabajando y en donde se encontrarán nuestras tablas.
Posteriormente, para crear las tablas utilizaremos la instrucción CREATE TABLE seguido del nombre que le asignaremos a nuestra tabla.
Luego, agregaremos cada uno de los campos a nuestra tabla, que serán las columnas de la misma. Para esto solo añadimos el nombre de la columna seguido del tipo de dato que estaremos almacenando.
Consultas básicas en SQL
Cláusula SELECT FROM
La función SELECT * FROM es una instrucción básica en SQL que se utiliza para recuperar todos los datos de todas las columnas de una tabla en una base de datos. En otras palabras, esta instrucción se utiliza para seleccionar todas las filas y todas las columnas de una tabla.
La sintaxis básica de la instrucción SELECT * FROM es la siguiente:
|
SELECT * FROM nombre_de_la_tabla; |
Donde «nombre_de_la_tabla» es el nombre de la tabla que contiene los datos que se desean recuperar.
Al utilizar la instrucción SELECT * FROM, se seleccionan todos los datos de todas las columnas de la tabla especificada. Esto es útil cuando se desea obtener todos los datos de una tabla sin tener que especificar las columnas individualmente.
También es importante tener en cuenta que seleccionar todas las columnas en una tabla puede ser ineficiente si la tabla contiene muchas columnas o muchas filas. En estos casos, puede ser más eficiente seleccionar solo las columnas específicas que se necesitan en lugar de todas las columnas mediante la sintaxis SELECT nombre_columna_1, nombre_columna_2, ... FROM nombre_de_la_tabla.
En nuestro ejemplo quedaría de la siguiente manera:
|
SELECT * FROM ingeniero; |
El asterisco (*) se utiliza para seleccionar todas las columnas de la tabla. Si se quisiera seleccionar solo ciertas columnas, puedes reemplazar el asterisco con los nombres de las columnas separados por comas.
|
SELECT nombre, apellido FROM ingeniero; |
Cláusula JOIN
La instrucción JOIN en SQL se utiliza para combinar datos de dos o más tablas relacionales en una sola consulta. La unión de tablas se realiza mediante columnas comunes (generalmente claves primarias y foráneas) que se usan para establecer relaciones entre las tablas.
En una consulta JOIN, se especifica la forma en que se combinan las tablas mediante una cláusula JOIN (INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN, entre otros). La cláusula JOIN indica qué registros deben ser seleccionados de cada tabla, según los valores de las columnas comunes.
La instrucción JOIN es útil cuando se trabaja con bases de datos relacionales que contienen múltiples tablas interconectadas mediante relaciones. Al combinar datos de diferentes tablas, es posible obtener información más completa y detallada que si se consulta una sola tabla.
Operación INNER JOIN
Supongamos que deseas obtener una lista de todas las tareas asignadas a un ingeniero en particular, incluyendo información sobre el proyecto correspondiente. Para ello, debes realizar una operación INNER JOIN entre las tablas «tarea» e «ingeniero» y otra INNER JOIN entre las tablas «tarea» y «proyecto».
|
SELECT tarea.id, tarea.fecha_inicio, tarea.fecha_termino, tarea.fecha_estimada, proyecto.nombre_proyecto FROM tarea INNER JOIN ingeniero ON tarea.id_ingeniero = ingeniero.id INNER JOIN proyecto ON tarea.id_proyecto = proyecto.id WHERE ingeniero.nombre = 'Nombre del Ingeniero'; |
En este ejemplo, la consulta selecciona las columnas «id», «fecha_inicio», «fecha_termino», «fecha_estimada» y «nombre_proyecto» de las tablas «tarea», «ingeniero» y «proyecto». La cláusula INNER JOIN se utiliza para combinar los datos de las tablas «tarea», «ingeniero» y «proyecto» según las columnas «id_ingeniero» y «id_proyecto», que se usan como claves foráneas. La cláusula WHERE se emplea para filtrar las tareas según el nombre del ingeniero especificado.
Operación LEFT JOIN
Supongamos que se desea obtener una lista de todos los ingenieros en la base de datos, junto con la información de los proyectos en los que han trabajado (si los hay). Para ello, puedes realizar una operación LEFT JOIN entre las tablas «ingeniero» y «tarea» y otra LEFT JOIN entre las tablas «tarea» y «proyecto».
|
SELECT ingeniero.id, ingeniero.nombre, ingeniero.apellido, proyecto.nombre_proyecto FROM ingeniero LEFT JOIN tarea ON ingeniero.id = tarea.id_ingeniero LEFT JOIN proyecto ON tarea.id_proyecto = proyecto.id; |
En este ejemplo, la consulta selecciona las columnas «id», «nombre» y «apellido» de la tabla «ingeniero», y la columna «nombre_proyecto» de la tabla «proyecto». La cláusula LEFT JOIN se utiliza para combinar los datos de las tablas «ingeniero», «tarea» y «proyecto» según las columnas «id_ingeniero» e «id_proyecto». La cláusula LEFT JOIN permite seleccionar todas las filas de la tabla «ingeniero», incluso si no hay coincidencias en la tabla «tarea». En este caso, la información del proyecto aparecerá como NULL si un ingeniero no ha trabajado en ningún proyecto.
Operación RIGHT JOIN
Supongamos que deseas obtener una lista de todos los proyectos en la base de datos, junto con la información de los ingenieros que han trabajado en ellos (si los hay). Para ello, puedes realizar una operación RIGHT JOIN entre las tablas «proyecto» y «tarea» y otra RIGHT JOIN entre las tablas «tarea» e «ingeniero».
|
SELECT proyecto.id, proyecto.nombre_proyecto, ingeniero.nombre, ingeniero.apellido FROM proyecto RIGHT JOIN tarea ON proyecto.id = tarea.id_proyecto RIGHT JOIN ingeniero ON tarea.id_ingeniero = ingeniero.id; |
En este ejemplo, la consulta selecciona las columnas «id», «nombre_proyecto», «nombre» y «apellido» de las tablas «proyecto» e «ingeniero». La cláusula RIGHT JOIN se utiliza para combinar los datos de las tablas «proyecto», «tarea» e «ingeniero» según las columnas «id_proyecto» e «id_ingeniero». La cláusula RIGHT JOIN permite seleccionar todas las filas de la tabla «proyecto», incluso si no hay coincidencias en la tabla «tarea» e «ingeniero». En este caso, la información del ingeniero aparecerá como NULL si un proyecto no ha tenido ningún ingeniero asignado.
Operación FULL OUTER JOIN
El FULL OUTER JOIN es un tipo de operación JOIN que devuelve todas las filas de ambas tablas, y donde las filas que no tienen una coincidencia en la otra tabla se llenan con valores NULL. En MySQL, la sintaxis para hacer un FULL OUTER JOIN es usar la cláusula LEFT JOIN y RIGHT JOIN en una misma consulta.
|
SELECT ingeniero.id, ingeniero.nombre, proyecto.id, proyecto.nombre_proyecto FROM ingeniero FULL OUTER JOIN tarea ON ingeniero.id = tarea.id_ingeniero FULL OUTER JOIN proyecto ON tarea.id_proyecto = proyecto.id; |
En este ejemplo, la consulta selecciona las columnas «id» y «nombre» de la tabla «ingeniero» y las columnas «id» y «nombre_proyecto» de la tabla «proyecto». La cláusula FULL OUTER JOIN se utiliza para combinar los datos de las tablas «ingeniero», «tarea» y «proyecto» según las columnas «id_ingeniero» e «id_proyecto». En este caso, la consulta devuelve todas las filas de ambas tablas, incluso si no hay coincidencias en la otra tabla. Las filas que no tienen una coincidencia en la otra tabla se llenan con valores NULL.
Cláusula WHERE
La cláusula WHERE en SQL se utiliza para filtrar los resultados de una consulta según una o varias condiciones especificadas. La cláusula WHERE se coloca después de la cláusula FROM en una consulta SELECT y permite especificar una condición que debe cumplir cada fila para ser incluida en el resultado.
La sintaxis básica de la cláusula WHERE es la siguiente:
|
SELECT columna1, columna2, ... FROM tabla WHERE condicion; |
En la cláusula WHERE, la «condición» es una expresión booleana que evalúa a TRUE o FALSE para cada fila en la tabla. Solo las filas para las que la condición es TRUE se incluyen en el resultado.
Supongamos que queremos obtener todos los proyectos en los que está trabajando un ingeniero específico. Para ello, podemos utilizar la cláusula WHERE para filtrar los resultados según el id del ingeniero que nos interesa.
Aquí te dejo un ejemplo de cómo sería la consulta utilizando la cláusula WHERE en nuestras tablas «ingeniero», «proyecto» y «tarea»:
|
SELECT proyecto.nombre_proyecto, tarea.fecha_inicio, tarea.fecha_termino FROM proyecto INNER JOIN tarea ON proyecto.id = tarea.id_proyecto WHERE tarea.id_ingeniero = 1; |
En este ejemplo, la consulta selecciona las columnas «nombre_proyecto», «fecha_inicio» y «fecha_termino» de las tablas «proyecto» y «tarea», respectivamente. La cláusula INNER JOIN se utiliza para combinar las filas de ambas tablas según la columna «id_proyecto». La cláusula WHERE se utiliza para filtrar los resultados y seleccionar solo las filas en las que la columna «id_ingeniero» de la tabla «tarea» sea igual a 1 (suponiendo que 1 es el id del ingeniero que nos interesa).
Cláusula GROUP BY
La cláusula GROUP BY en SQL se utiliza para agrupar filas en una consulta según los valores de una o varias columnas. Esta cláusula permite resumir los datos en un conjunto de resultados para poder realizar operaciones de agregación, como sumas, promedios o cuentas, sobre cada grupo de filas.
La sintaxis básica de la cláusula GROUP BY es la siguiente:
|
SELECT columna1, columna2, ..., funcion_agregacion(columna) FROM tabla GROUP BY columna1, columna2, ...; |
En esta sintaxis, «columna1», «columna2», etc., son las columnas por las que se desea agrupar los resultados. Por su parte, «funcion_agregacion» es una función que se aplica a cada grupo de filas y devuelve un valor agregado, como la suma o el promedio de una columna.
|
SELECT proyecto.nombre_proyecto, ingeniero.nombre, COUNT(tarea.id) as cantidad_tareas FROM tarea JOIN proyecto ON tarea.id_proyecto = proyecto.id JOIN ingeniero ON tarea.id_ingeniero = ingeniero.id GROUP BY proyecto.nombre_proyecto, ingeniero.nombre; |
En esta consulta, se utiliza la cláusula GROUP BY para agrupar las tareas por proyecto y empleado. La función COUNT se usa para contar el número de tareas que cada empleado tiene asignadas en cada proyecto. La consulta une las tablas «tarea», «proyecto» e «ingeniero» mediante las claves foráneas «id_proyecto» e «id_ingeniero».
Cláusula HAVING
La cláusula HAVING en SQL se utiliza para filtrar los resultados de una consulta que emplea la cláusula GROUP BY. Mientras que la cláusula WHERE filtra los resultados de una consulta antes de que se agrupen, la cláusula HAVING filtra los resultados después de la agrupación.
La sintaxis básica de la cláusula HAVING es la siguiente:
|
SELECT columna1, columna2, ..., funcion_agregacion(columna) FROM tabla GROUP BY columna1, columna2, ... HAVING condicion; |
En esta sintaxis, «columna1», «columna2», etc. son las columnas por las que se agrupan los resultados. Por su parte, «funcion_agregacion» es una función que se aplica a cada grupo de filas y devuelve un valor agregado, como la suma o el promedio de una columna. En tanto que «condicion» es la condición que se utiliza para filtrar los resultados después de la agrupación.
Supongamos que deseas encontrar los ingenieros que tienen más de 5 tareas asignadas en total.
|
SELECT ingeniero.nombre, COUNT(tarea.id) as cantidad_tareas FROM tarea JOIN ingeniero ON tarea.id_ingeniero = ingeniero.id GROUP BY ingeniero.nombre HAVING COUNT(tarea.id) > 5; |
En esta consulta, se utiliza la cláusula GROUP BY para agrupar las tareas por el nombre del ingeniero. Luego se usa la función COUNT para contar el número de tareas que tiene cada uno. La cláusula HAVING se emplea para filtrar los resultados y mostrar solo los ingenieros que tienen más de 5 tareas asignadas en total.
Orden de ejecución de los comandos en SQL
Es importante entender la prioridad de ejecución de las cláusulas en una consulta SQL para poder escribir consultas correctamente.
La prioridad de ejecución de las cláusulas en una consulta SQL es la siguiente:
- FROM: especifica las tablas en las que se realiza la consulta.
- JOIN: se utiliza para combinar varias tablas.
- WHERE: para filtrar los resultados.
- GROUP BY: agrupa los resultados por una o varias columnas.
- HAVING: filtra los resultados agregados.
- SELECT: se usa para seleccionar las columnas que se muestran en los resultados.
- ORDER BY: se emplea para ordenarlos.
Es importante tener en cuenta que las cláusulas se ejecutan en el orden en que se muestran, pero esto no significa necesariamente que deban aparecer en ese orden en la consulta. Por ejemplo, la cláusula WHERE se puede colocar antes o después de la cláusula JOIN, pero su efecto será el mismo.
Cómo optimizar las consultas en SQL
Utiliza índices
Los índices son una forma de acelerar las búsquedas en una base de datos. Debes asegurarte de crear índices en las columnas que se utilizan con frecuencia en las consultas.
Supongamos que la columna «nómina» de la tabla «ingeniero» se utiliza frecuentemente en las consultas.
|
CREATE INDEX idx_nomina ON ingeniero (nomina); |
2. Evita las subconsultas
Las subconsultas pueden ralentizar las consultas. En lugar de utilizarlas, intenta usar joins o expresiones de tabla comunes (CTE).
En lugar de emplear una subconsulta para obtener el número de tareas asignadas a cada ingeniero, podemos utilizar una expresión de tabla común:
|
WITH cte_num_tareas AS ( SELECT id_ingeniero, COUNT(*) AS num_tareas FROM tarea GROUP BY id_ingeniero ) SELECT i.nombre, i.apellido, cte.num_tareas FROM ingeniero i INNER JOIN cte_num_tareas cte ON i.id = cte.id_ingeniero; |
3. Evita el uso de operaciones costosas
Algunas operaciones, como la ordenación o el cálculo de funciones matemáticas complejas, pueden ser costosas y ralentizar las consultas. Intenta evitar estas operaciones innecesarias siempre que sea posible.
Supongamos que queremos obtener el promedio de duración de las tareas en días. Podríamos utilizar la función AVG y convertir la diferencia entre las fechas a días usando la función DATEDIFF:
|
SELECT AVG(DATEDIFF(fecha_termino, fecha_inicio)) AS promedio_duracion FROM tarea; |
4. Utiliza el tipo de datos adecuado
Usa el tipo de datos más adecuado para cada columna. Por ejemplo, si una columna solo contiene valores enteros positivos, emplea el tipo de datos int unsigned en lugar de varchar.
Supongamos que la columna «id» de la tabla «proyecto» solo contiene valores enteros positivos. Podríamos cambiar el tipo de datos de esta columna de int a int unsigned para optimizar el almacenamiento y la búsqueda:
|
ALTER TABLE proyecto MODIFY COLUMN id INT UNSIGNED NOT NULL AUTO_INCREMENT; |
5. Limita el número de resultados
Si solo necesitas mostrar algunos resultados, utiliza la cláusula LIMIT para limitar el número de resultados devueltos por la consulta.
Supongamos que queremos obtener los 10 proyectos más recientes. Podríamos usar la cláusula LIMIT para limitar el número de resultados devueltos por la consulta:
|
SELECT * FROM proyecto ORDER BY id DESC LIMIT 10; |
6. Evita el uso de SELECT *
Si solo necesitas algunas columnas, especifica las columnas que deseas seleccionar en lugar de utilizar SELECT *.
En lugar de seleccionar todas las columnas de la tabla «ingeniero», podríamos especificar solo las columnas que necesitamos:
|
SELECT nombre, apellido, nomina FROM ingeniero; |
7. Mantén la base de datos optimizada
Debes realizar tareas de mantenimiento en la base de datos, como la eliminación de registros innecesarios o la optimización de las tablas.
Podríamos realizar tareas de mantenimiento, como la eliminación de registros innecesarios, la optimización de las tablas y la actualización de las estadísticas de la base de datos:
|
-- Eliminar registros antiguos DELETE FROM tarea WHERE fecha_termino < '2022-01-01'; -- Optimizar tabla tarea OPTIMIZE TABLE tarea; -- Actualizar estadísticas de la base de datos ANALYZE TABLE tarea; |
En resumen, en SQL, una consulta es un comando que se utiliza para recuperar información de una o más tablas de una base de datos.
Como viste, una consulta típica consta de tres partes principales:
- La cláusula SELECT: esta parte indica qué columnas se desean recuperar de la base de datos. Por ejemplo, SELECT nombre, edad, dirección recuperará los valores de las columnas «nombre», «edad» y «dirección» de la tabla especificada en la consulta.
- La cláusula FROM: esta parte indica la tabla o tablas de las que se van a recuperar los datos. Por ejemplo, FROM usuarios recuperará los datos de la tabla «usuarios».
- La cláusula WHERE: esta parte se utiliza para especificar una condición que debe cumplirse para que los datos se recuperen. Por ejemplo, WHERE edad > 18 recuperará los datos solo de los usuarios cuya edad sea mayor de 18 años.
Estas tres partes se combinan para crear una consulta completa. Las consultas también pueden incluir otras cláusulas opcionales, como ORDER BY (para ordenar los resultados según una columna específica) y GROUP BY (para agrupar los resultados por valores comunes en una columna).
Finalmente, una consulta en SQL es un comando utilizado para recuperar información de una base de datos, y consta de una cláusula SELECT para indicar las columnas que se desean recuperar, una cláusula FROM para especificar la tabla o tablas de donde se obtendrán los datos, y una cláusula WHERE para establecer una condición para la selección de los mismos.



